Here are two national presidential primary polling graphs. Both show the same basic scale, and both tell the same basic story: A Clinton lead throughout 2007, followed by a sudden jump in Obama support in January, and a lead maintained by him from there on:
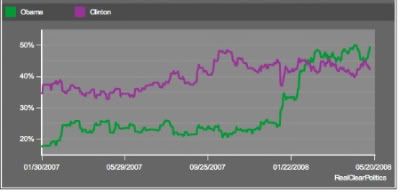
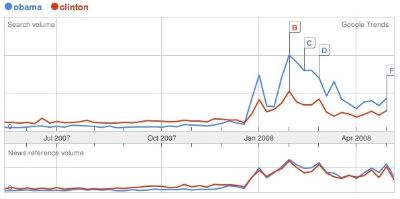
Simple, right? Various polling data usually reflects each other, in part because it attempts to choose a random sample of people to use as a predictor. But these two polls aren't equal. In fact, the one on the bottom isn't a poll at all: It's a graph of Google searches for "Obama" and "Clinton."
Fascinating, isn't it? They're so similar--they show the same ebb and flow in 2008, with a wide Obama margin in February, when he was winning all those states, and then a compression again once Ohio and Pennsylvania came in, followed finally by a widening gulf again once the North Carolina blowout and Indiana squeaker happened.
Yet one is reflective of expensive and extensive polling (it is, in fact, an average of numerous national polls)--a reflection of stated support for a candidate--and the other is simply a record of who searched for their names--positively, negatively, actively, or passively. And yet they mirror each other. So what's the point of dropping millions into polling then?
When people talk about "the wisdom of crowds" this is what they're talking about. Because here's nothing but crowdsourced data, yet it's a perfect reflector of the national attitude. If it holds up, it's bad news for John McCain.

3 comments:
question ...
do you think techcrunch got this idea from you via an unknown path?
or ....
are ideas simply in the atmosphere, and no one can really claim them?
I think they'd give credit if it was from me. I think it's just reflective of the times. They were late to the party though!
Hey, I actually am the author of the original article, which got Slashdotted, from which TechCrunch found out about it.
I wrote that article a couple weeks after this one came out, so kudos to Sinker for beating me to it. But I hadn't seen this article before writing mine or, like Sinker said, I would've given him credit for the idea. My analysis goes into more depth, if anyone is interested in checking it out.
Post a Comment